实战 · 打造会记忆的AI 写作搭档(一):多 Agent 架构进化
写长篇小说时,最痛的不是“写不出来”,而是“写着写着就忘了自己写过什么”:伏笔埋没埋好?角色是不是上一章已经受伤?某个设定到底什么时候定下来的?当篇幅走到几十万字后,这些信息如果只靠人脑和零散笔记维持,很快就会失控。
FantasyNovelAgent 就是从这个需求出发,一点点长出来的:先是一个能跑的 Python 脚本,后来加上动态记忆与自动归档,再到支持多端同步,最后开始迈向前后端分离与云原生存储的雏形。本文复盘这条进化路径,并把关键取舍讲清楚,供同类项目参考。
如果你想先体验一下这个项目,这里有一个在线 Demo:demo online(欢迎试用)。为了避免滥用与泄露成本,Demo 需要你在设置里填写自己的大模型 API Key 后才会真正调用模型能力。
1. 核心功能:AI 如何像搭档一样写作?
在谈论技术架构之前,先来看看它能做什么。FantasyNovelAgent 并不是一个简单的“续写工具”,它更像是一个由多名专家组成的“写作工作室”。
1.1 灵感推演(Brainstorming)
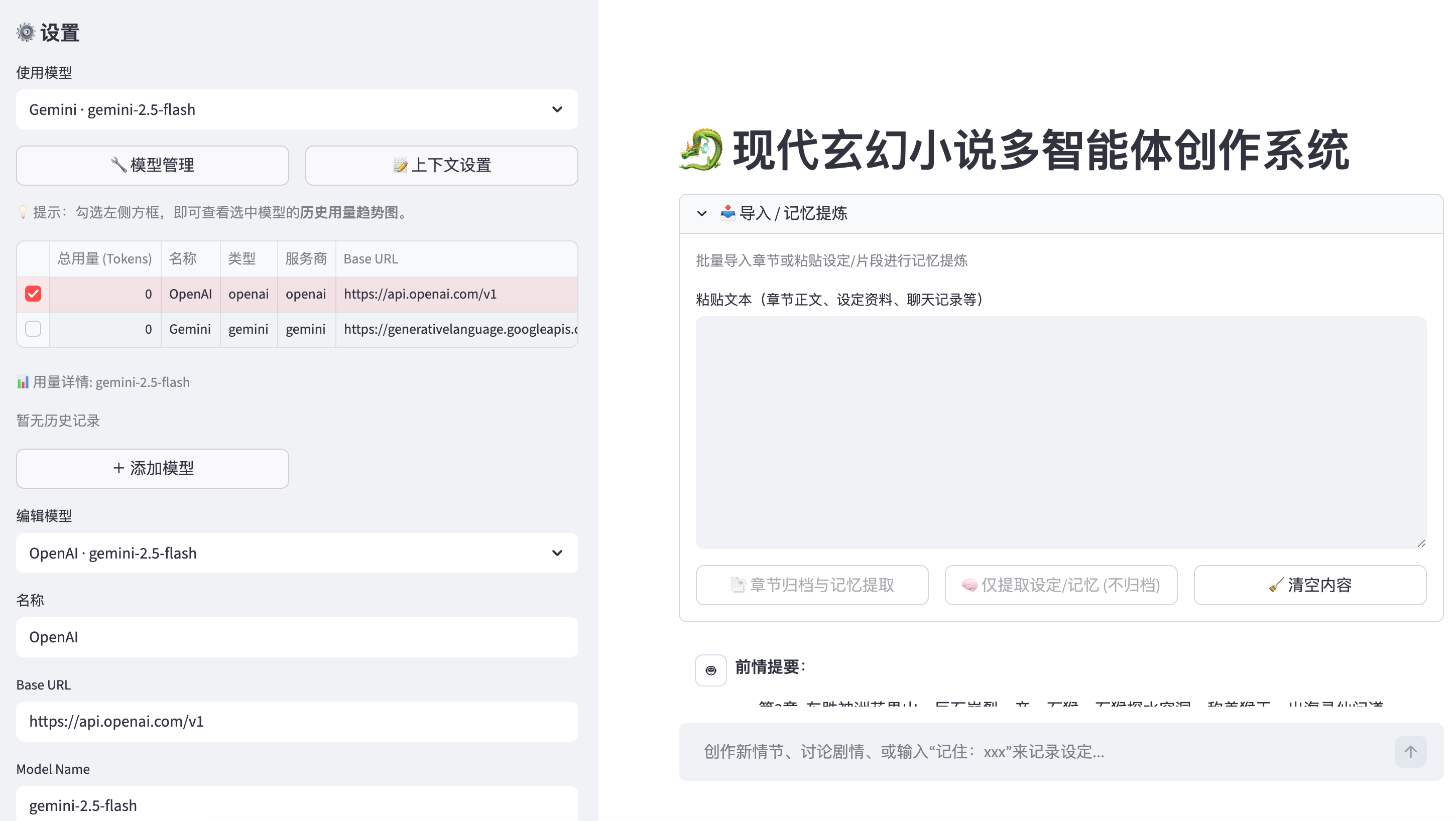
当你卡文时,点击“自动推演”,系统会基于最近 10 章的剧情走向、未填的坑(未来规划)以及世界观设定,为你提供 3 个截然不同的剧情分支。你可以从中选择一个,或者融合它们的创意。
1.2 沉浸式写作(Writing & Polishing)
- Muse(缪斯):负责“骨架”。它会根据你选定的大纲,快速生成 2000 字左右的正文初稿,重点在于情节推进和伏笔埋设。
- Stylist(风格师):负责“皮肉”。它会将初稿进行深度润色,将平淡的“他出了一拳”改写为“拳风呼啸,裹挟着雷霆万钧之势…”,确保文风符合“现代玄幻爽文”的调性。
1.3 动态记忆系统(Active Memory)
这是本项目的杀手锏。你不需要手动维护“角色表”或“物品栏”。
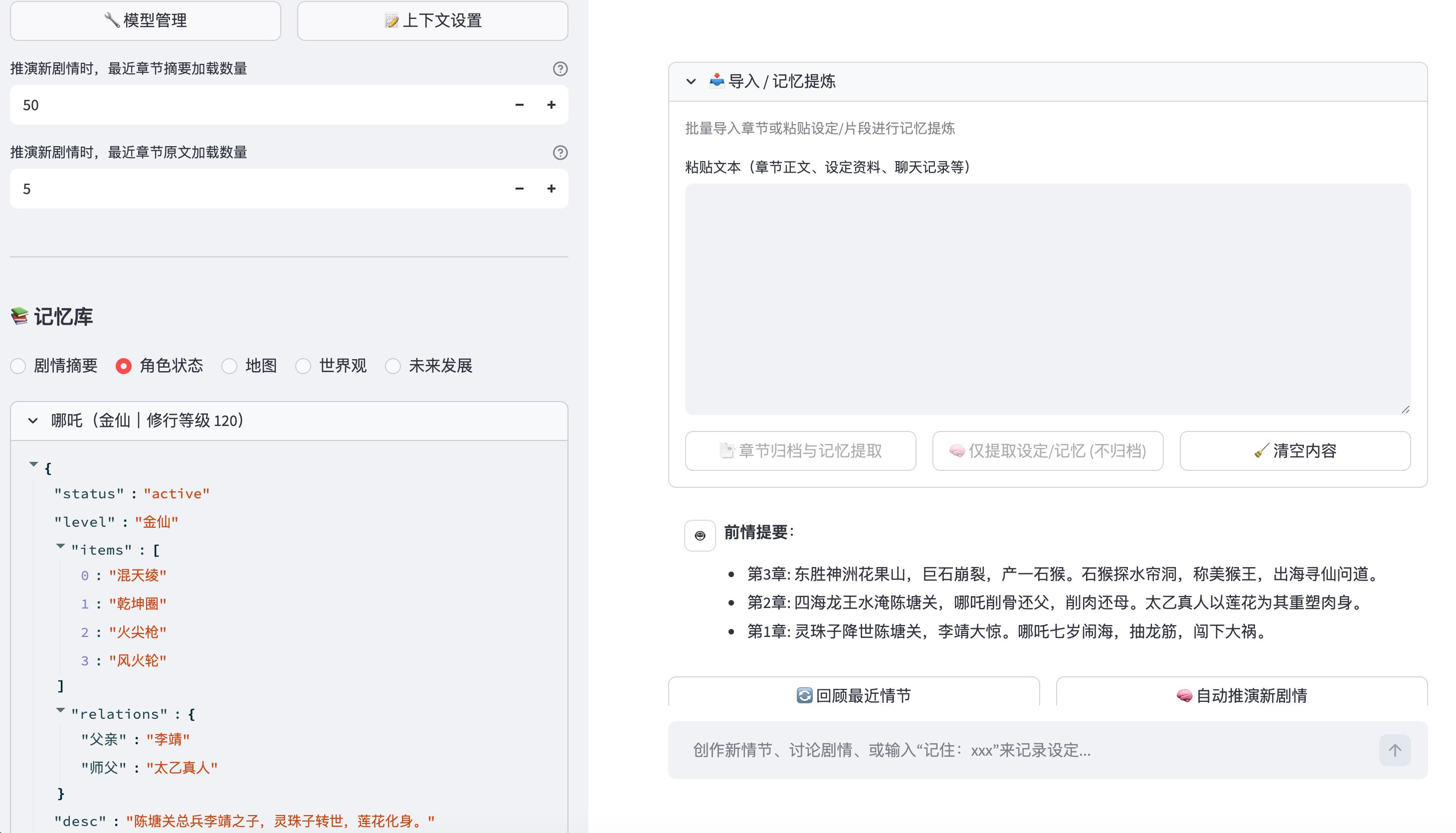
- Archivist(记录官) 会在后台默默工作。当你写完一章,它会自动分析文本:“主角获得了‘青云剑’”、“‘李四’重伤死亡”。
- 这些信息会被提取为结构化数据,存入 SQLite 数据库。下一章写作时,AI 不会搞错主角手里拿的是刀还是剑。
graph TD
User[用户输入] --> Router{意图路由}
Router -->|写作| Muse[Muse 缪斯]
Router -->|润色| Stylist[Stylist 风格师]
Router -->|检查| Guard[Guard 守卫]
Context[(上下文构建)] --> Muse
Context --> Stylist
Muse --> Result[生成内容]
Result --> Archivist[Archivist 记录官]
Archivist -->|提取更新| Memory[(记忆库/DB)]
Memory --> Contextgraph TD
User[用户输入] --> Router{意图路由}
Router -->|写作| Muse[Muse 缪斯]
Router -->|润色| Stylist[Stylist 风格师]
Router -->|检查| Guard[Guard 守卫]
Context[(上下文构建)] --> Muse
Context --> Stylist
Muse --> Result[生成内容]
Result --> Archivist[Archivist 记录官]
Archivist -->|提取更新| Memory[(记忆库/DB)]
Memory --> Contextgraph TD
User[用户输入] --> Router{意图路由}
Router -->|写作| Muse[Muse 缪斯]
Router -->|润色| Stylist[Stylist 风格师]
Router -->|检查| Guard[Guard 守卫]
Context[(上下文构建)] --> Muse
Context --> Stylist
Muse --> Result[生成内容]
Result --> Archivist[Archivist 记录官]
Archivist -->|提取更新| Memory[(记忆库/DB)]
Memory --> Contextgraph TD
User[用户输入] --> Router{意图路由}
Router -->|写作| Muse[Muse 缪斯]
Router -->|润色| Stylist[Stylist 风格师]
Router -->|检查| Guard[Guard 守卫]
Context[(上下文构建)] --> Muse
Context --> Stylist
Muse --> Result[生成内容]
Result --> Archivist[Archivist 记录官]
Archivist -->|提取更新| Memory[(记忆库/DB)]
Memory --> Context1.4 逻辑守卫(Logic Guard)
想让主角突然学会敌对门派的禁术?Guard 会立刻跳出来警告你:“检测到设定冲突:该禁术需要‘魔道血脉’,而主角目前是‘纯阳之体’。”
1.5 大模型策略(LLM Strategy)
为了达到最佳效果,我并未绑定单一模型,而是采用了 “各司其职” 的策略:
| 任务类型 | 推荐模型 | 理由 |
|---|---|---|
| 逻辑检查 / 复杂推演 | DeepSeek R1 / OpenAI o1 | 这类“推理系”模型在输出前会进行长思维链(CoT)思考,非常适合发现剧情漏洞或设计复杂的智斗环节。 |
| 正文撰写 / 润色 | Claude 3.5 Sonnet / GPT-4o | 文笔优美,语感自然,尤其擅长环境描写和情感渲染。 |
| 记忆提取 / 摘要 | Gemini Flash / DeepSeek V3 | 速度快、成本低、上下文窗口大,适合处理大量文本的分析任务。 |
2. 架构演进:从文件到数据库
在项目初期,为了快速验证想法,我采用了最简单的 “文件系统存储” 方案。
- 章节:每一章都是一个
.txt文件。 - 记忆:角色卡、世界观、剧情大纲分别存储为
character_db.json、world_settings.md等。 - 优势:开发极快,Git 版本控制友好,人眼可读。
- 劣势:随着章节增多(比如写到第 100 章),
data/目录下会散落成百上千个小文件。文件 I/O 变得频繁,且难以进行复杂的查询(比如“搜索所有提到‘青云剑’的章节”)。
3. 功能完善与自动化
随着核心逻辑跑通,我引入了更多工程化特性:
- 意图路由(Intent Router):根据用户的自然语言指令(“帮我写个打斗场景” vs “检查一下这章有没有 Bug”),自动调度不同的 Agent。
- 用量追踪:集成 Token 消耗统计,让创作成本一目了然。
- 自动化归档:用户点击“保存”的那一刻,系统不仅写入文件,还会触发一连串后台任务——更新摘要链、检查未来规划完成度等。
4. 部署:把 AI 装进树莓派
为了能随时随地写作,我把项目部署到了家里的 树莓派(Raspberry Pi) 上。
- 内网穿透:利用 Cloudflare Tunnel,无需公网 IP 也能通过自定义域名安全访问。
- 自动化运维:编写
systemd服务脚本,实现开机自启和进程守护。 - 一键部署:开发
deploy.sh脚本。在 Mac 上写完代码,一条命令即可自动完成 Git 提交、代码同步(Rsync)和远程服务重启。
5. 关键转折:SQLite 架构重构
这是项目近期最大的一次底层改造。
随着“文件即数据库”模式的弊端日益显现,我决定引入 SQLite。
5.1 为什么要改?
- 数据完整性:文件系统缺乏事务支持,写入中断可能导致 JSON 损坏。
- 查询能力:我需要更强大的检索能力来支撑 AI 的“长期记忆”。
- 部署复杂度:同步 1000 个小文件远比同步 1 个
.db文件更容易出错。
5.2 改造方案
我设计了一个 抽象存储层(Storage Layer):
- 接口化:将
memory_manager.py中的业务逻辑与底层 I/O 解耦。 - 数据迁移:编写脚本将旧有的 JSON/TXT 数据无缝导入
novel.db。 - 混合架构:
- 核心数据(章节、记忆、草稿)→ SQLite
- 配置与日志(API Key、Logs)→ 独立 JSON 文件(便于 Git 忽略与日志轮转)
5.3 双向同步流
为了防止“在树莓派上写了新章节,却被 Mac 上的旧代码覆盖”的惨剧,我在部署脚本中加入了 数据回滚保护:
- Sync Back:部署前,脚本先从树莓派拉取最新的
novel.db到本地。 - Backup:自动将拉取的数据提交到私有仓库备份。
- Push:只有在数据安全的前提下,才推送新代码到树莓派。
sequenceDiagram
participant Mac as 本地 Mac
participant GitHub as 备份仓库
participant Pi as 树莓派
Note over Mac: 运行 deploy.sh
Mac->>Pi: 1. 拉取远程数据(Sync Back)
Pi-->>Mac: 返回最新 novel.db
Mac->>GitHub: 2. 备份数据
Mac->>Pi: 3. 推送新代码 & DB(Rsync)
Mac->>Pi: 4. 重启服务(Systemd)sequenceDiagram
participant Mac as 本地 Mac
participant GitHub as 备份仓库
participant Pi as 树莓派
Note over Mac: 运行 deploy.sh
Mac->>Pi: 1. 拉取远程数据(Sync Back)
Pi-->>Mac: 返回最新 novel.db
Mac->>GitHub: 2. 备份数据
Mac->>Pi: 3. 推送新代码 & DB(Rsync)
Mac->>Pi: 4. 重启服务(Systemd)sequenceDiagram
participant Mac as 本地 Mac
participant GitHub as 备份仓库
participant Pi as 树莓派
Note over Mac: 运行 deploy.sh
Mac->>Pi: 1. 拉取远程数据(Sync Back)
Pi-->>Mac: 返回最新 novel.db
Mac->>GitHub: 2. 备份数据
Mac->>Pi: 3. 推送新代码 & DB(Rsync)
Mac->>Pi: 4. 重启服务(Systemd)sequenceDiagram
participant Mac as 本地 Mac
participant GitHub as 备份仓库
participant Pi as 树莓派
Note over Mac: 运行 deploy.sh
Mac->>Pi: 1. 拉取远程数据(Sync Back)
Pi-->>Mac: 返回最新 novel.db
Mac->>GitHub: 2. 备份数据
Mac->>Pi: 3. 推送新代码 & DB(Rsync)
Mac->>Pi: 4. 重启服务(Systemd)6. 过渡阶段:前后端分离(The Great Decoupling)
在迈向更“服务化”的架构之前,我意识到目前的 Streamlit 单体应用(Monolith)已经有些臃肿:UI 渲染、业务逻辑、数据库操作都挤在一个入口里。
为了支持未来可能的移动端 App 或多用户协作,我制定了 前后端分离 计划:
- 后端 API 化:引入 FastAPI,将
Muse、Guard等 Agent 的能力封装为标准 REST 接口(如/api/v1/brainstorm)。 - 前端轻量化:Streamlit 退化为纯粹的“前端面板”,只负责展示与发请求;未来也可以替换为 React/Vue。
- 独立部署:后端可单独运行在 Docker 容器中,为多个前端提供服务。
这一步虽然不涉及底层存储的变更,却是系统从“脚本”走向“平台”的关键跳板:一旦边界清晰,系统就能更自然地向多用户、权限隔离、灰度发布、异步任务等平台能力扩展。
7. 未来展望:云原生架构(Cloud Native)
阶段二:检索升级(SQLite + 向量检索的双系统)
当篇幅越来越长,单纯“把事实记住”还不够。我需要系统既能守住结构化事实(谁拿着什么、谁受了什么伤、哪些设定已生效),又能在写作时进行模糊召回(类似桥段、氛围语料、伏笔/回忆触发、人物语气一致性)。因此,我把下一阶段的目标定义为 SQLite + 向量检索的双系统:
- SQLite 继续负责“事实与结构化记忆”:角色状态、设定、时间线等可校验、可追溯、可做约束判断的数据。
- 向量检索负责“模糊召回”:相似片段、相关对话、同类场景的写作参考,以及能激活“伏笔/回忆”的语义关联内容。
对应的交付物会更工程化、更可迭代:
- 一套可插拔的检索模块:对上层暴露统一接口
retrieve(query) -> passages[],底层可以替换实现(SQLite 内置 / sidecar 索引 / 远程向量库)。 - 上下文拼装规则:写作/润色/问答时,统一按“结构化事实 + 向量召回片段(TopK)+ 最近章节”的优先级拼装上下文,保证既可靠又有灵感来源。
渐进式实现上,我会优先走一条“本地闭环 → 再替换”的路径:
- 先本地:在 SQLite 增加
embeddings表,或使用 sidecar 文件索引,先把“向量召回闭环”跑通,验证 chunk 切分、召回质量与上下文拼装策略是否有效。 - 再替换:当需要多设备/多用户/更大规模时,再迁移到 pgvector/Milvus/Pinecone 等更适合在线检索与并发的系统。
这里有两个我认为必须守住的设计原则:
- chunk 切分策略比“选哪家向量库”更重要:按段落、事件、对话来切,往往比单纯按固定字数切,能显著提升召回的可用性(尤其在“人物语气一致性”和“伏笔回收”这类任务上)。
- 事实优先(Conflict Resolution):当向量召回的片段与 SQLite 的结构化事实冲突时,以 SQLite 为准。向量召回提供灵感与上下文,而不是修改世界观的“事实来源”。
阶段三:云原生雏形(数据库 + 对象存储)
SQLite 只是第一步。随着小说篇幅增长到百万字级别,我仍然会规划 “数据库 + 对象存储” 的形态:
| 数据类型 | 存储方案 | 理由 |
|---|---|---|
| 元数据/索引 | Cloudflare D1 / AWS RDS | 章节列表、角色关系图等需要高频、复杂的结构化查询。 |
| 正文/素材 | Cloudflare R2 / AWS S3 | 小说正文、插图体积大但读写简单,分离存储可显著降低数据库负载。 |
为了让“多端写作 + 多端同步”真正可靠,下一阶段的核心将不再是“能不能生成”,而是“能不能长期稳定地治理创作资产”:数据一致性、备份与回滚、权限与审计、成本与可观测性,都会逐步成为架构演进的主旋律。
结语
FantasyNovelAgent 的进化史,也是一个开发者从“能用就行”到追求“架构之美”的缩影。每一次重构,都是为了让 AI 助手更稳定、更聪明,从而让我能专注于最重要的事情——讲好一个故事。